第五講:Perceiving Objects and Scenes
出自KMU Wiki
(修訂版本間差異)
| 在2014年1月14日 (二) 02:55所做的修訂版本 (編輯) Woody (對話 | 貢獻) (→完形心理學) ←上一個 |
在2014年1月14日 (二) 02:59所做的修訂版本 (編輯) (撤銷) Woody (對話 | 貢獻) (→場景知覺(Gist of the Scene)) 下一個→ |
||
| 第134行: | 第134行: | ||
| *在一連串呈現之前看到目標圖片或只是提示語(如:小女生在拍手) | *在一連串呈現之前看到目標圖片或只是提示語(如:小女生在拍手) | ||
| *結果受試者都可以看得到 | *結果受試者都可以看得到 | ||
| - | + | *參照第109頁 figure 5.33 | |
| *Li Fei-Fei (2007) | *Li Fei-Fei (2007) | ||
| *利用masking每張圖片呈現27到500毫秒,每張圖片呈現完之後會呈現一個mask來精確控制刺激呈現時間 | *利用masking每張圖片呈現27到500毫秒,每張圖片呈現完之後會呈現一個mask來精確控制刺激呈現時間 | ||
| *結果67ms 即可辨識(看到有人 :p) | *結果67ms 即可辨識(看到有人 :p) | ||
| - | + | *參照第110頁 figure 5.34 | |
| ===Masking=== | ===Masking=== | ||
| *masking procedure | *masking procedure | ||
| 第150行: | 第150行: | ||
| **Degree of expansion | **Degree of expansion | ||
| **Color | **Color | ||
| - | + | *參照第110頁 figure 5.35 | |
| ===Regularity=== | ===Regularity=== | ||
| - | + | *參照第111頁 figure 5.36 | |
| ===light-from-above heuristic=== | ===light-from-above heuristic=== | ||
| - | + | *參照第111頁 figure 5.37 | |
| *實例 | *實例 | ||
| - | + | *參照第112頁 figure 5.38 | |
| - | + | ||
| *旋轉 | *旋轉 | ||
| [[Image:05light-from-above heuristic4.png]] | [[Image:05light-from-above heuristic4.png]] | ||
| 第176行: | 第175行: | ||
| *然後再快速閃現另一組圖片(圖5.39右) | *然後再快速閃現另一組圖片(圖5.39右) | ||
| *當後面出現的這張圖片為麵包的時候,受試者的正確率較高。 | *當後面出現的這張圖片為麵包的時候,受試者的正確率較高。 | ||
| - | + | *參照第113頁 figure 5.39 | |
| *multiple personalities of blob:Oliva & Torralba(2007) | *multiple personalities of blob:Oliva & Torralba(2007) | ||
| - | + | *參照第113頁 figure 5.40 | |
| ===The role of inference in perception=== | ===The role of inference in perception=== | ||
| - | + | *參照第113頁 figure 5.41 | |
| ===theory of unconscious inference=== | ===theory of unconscious inference=== | ||
| *當我們面對不清楚的刺激時,視覺系統會根據其他各種條件,比如過去經驗,去推測當下的刺激為何。這樣的知覺推理歷程稱之為theory of unconscious inference | *當我們面對不清楚的刺激時,視覺系統會根據其他各種條件,比如過去經驗,去推測當下的刺激為何。這樣的知覺推理歷程稱之為theory of unconscious inference | ||
在2014年1月14日 (二) 02:59所做的修訂版本
Perceiving Objects and Scenes
Scenes
- 參照第94頁 封面
- 日常所見
- 參照第96頁 figure 5.1
- 困難所在
- 參照第96頁 figure 5.2
臉形辨識
- 困難處之一(角度)
- 參照第97頁 figure 5.3
- 在家中的畫面
- 機器人分析與錯誤
- 參照第97頁 figure 5.4
機器視覺


- 車速最高 50Km/hr
- 平均22Km/hr
Spirit in Mars
- 2004-1-4
- Sashimi(生魚片)

- Spirit

- 登陸艇

- 機械臂

- Adirondack
- 形狀類似美國阿爾崗金族印第安人的帳篷故得名

- get a X-ray

Optic
- 成像
- 參照98第頁 figure 5.5
Inverse projection problem
- 參照第98頁 figure 5.6
- 又稱 Inverse Optics
An environmental sculpture by Thomas Macaulay
- 從二樓陽台看
- 參照第98頁 figure 5.7(a)
- 從一樓看
- 參照第98頁 figure 5.7(b)
- 找一找鉛筆和眼鏡

這些人是誰?
- 參照第99頁 figure 5.9
Prince Charies, Woody Allen, Bill Clinton, Saddam Hussein, Richard Nixon, Princess Diana
從不同角度看
- 參照第99頁 figure 5.10
哪些照片是同一個人?

- 參照第100頁 figure 5.11
完形心理學
- 根據這些點(dot)累積創造出我們對臉的知覺的嗎?
- 參照第100頁 figure 5.13
似動現象(Apparent Movement)
- 由左至右的跑馬燈,似動現象(Apparent Movement)
- 參照第101頁 figure 5.14
- 參照第101頁 figure 5.15
錯覺輪廓(Illusory Contour)

Illusory contour
- 參照第102頁 figure 5.16
Good continuation
- 參照第102頁 figure 5.17
- 參照第102頁 figure 5.18
Pragnanz
- 參照第103頁 figure 5.19
相似性 law of similarity
- 相似的刺激傾向被知覺為一體
- 參照第103頁 figure 5.20
- Similarity ?
- 參照第103頁 figure 5.21
proximity
- 參照第103頁 figure 5.22
- 共同區域(Common Region,圖5.23a)、
- 連結律(Uniform Connectedness,圖5.23b)、
- 參照第104頁 figure 5.23
- 自然情境
- 參照第104頁 figure 5.24
- Common fate

12張臉孔在內?
- 具有意義或對觀察者較熟悉的刺激,會被視為一體,所以初看為一幅畫

你看到什麼?

- 知覺到的其中一個物體,另一個就成為背景
- 參照第105頁 figure 5.25
- 參照第105頁 figure 5.26
- (a)實驗呈現方式
- (b)當深色方塊被看成背景,則小黑點落在小方塊邊界上
- (c)當被看成中間有孔的深色方塊,則小黑點落在黑色方塊邊界上
- Figure ground separation 圖形背景分離
- 參照第105頁 figure 5.27
- 自然scene中的背景
- 參照第106頁 figure 5.28
convex region
- 參照第106頁 figure 5.29
meaningfulness
- 參照第107頁 figure 5.30
- 參照第107頁 figure 5.31
- face ??
- 參照第108頁 figure 5.32
Gestalt law as Heuristics

Recognition by component

Non-accidental properties


- 上面的三條線--------------------------------------------------------------------上面的兩條線
- 都是非偶發特性(non-accidental properties)
- Biederman的實驗

- Nonaccidental properties
- What's this?




- 6個geons的飛機





- 3個geons的飛機
場景知覺(Gist of the Scene)
- Mary Potter(1976)快速呈現16張複雜場景圖片,每張只呈現250毫秒。
- 在一連串呈現之前看到目標圖片或只是提示語(如:小女生在拍手)
- 結果受試者都可以看得到
- 參照第109頁 figure 5.33
- Li Fei-Fei (2007)
- 利用masking每張圖片呈現27到500毫秒,每張圖片呈現完之後會呈現一個mask來精確控制刺激呈現時間
- 結果67ms 即可辨識(看到有人 :p)
- 參照第110頁 figure 5.34
Masking
- masking procedure
- 抵消persistence of vision

Global Image Feature
- Oliva and Torralba (2001, 2006)
- Degree of naturalness
- Degree of openness
- Degree of roughness
- Degree of expansion
- Color
- 參照第110頁 figure 5.35
Regularity
- 參照第111頁 figure 5.36
light-from-above heuristic
- 參照第111頁 figure 5.37
- 實例
- 參照第112頁 figure 5.38
- 旋轉

Semantic Regularity

- Hollingworth (2005)
- 前圖為例,條件為二
- 目標出現
- 目標不出現
- 作業
- 目標出現在何處
- 目標該出現在何處(在無目標條件下)
- 結果
- 小圓:目標出現時
- 大圓:目標不出現時
- 前圖為例,條件為二
- Palmer (1975)
- 先呈現給受試者流理台的圖片(圖5.39左)
- 然後再快速閃現另一組圖片(圖5.39右)
- 當後面出現的這張圖片為麵包的時候,受試者的正確率較高。
- 參照第113頁 figure 5.39
- multiple personalities of blob:Oliva & Torralba(2007)
- 參照第113頁 figure 5.40
The role of inference in perception
- 參照第113頁 figure 5.41
theory of unconscious inference
- 當我們面對不清楚的刺激時,視覺系統會根據其他各種條件,比如過去經驗,去推測當下的刺激為何。這樣的知覺推理歷程稱之為theory of unconscious inference
- likelihood principle
- Bayesian inference
Neurons for grouping
原來對垂直線段有最佳反應的神經細胞(a),若置於其它隨機角度的線段中,反應會受到抑制(b),但若置於具有共線關係的線段中,便又使得反應增強(c)

Contextual modulation
- Lamme (1995)
- 如果線條符合V1細胞的接受區形式且在「圖形」中:反應(a)
- 如果線條符合V1細胞的接受區形式但不在「圖形」中:不反應(b)

Sensory coding
- 在臉部知覺的部分,以下幾個區域會有怎樣的反應?

Grill-Spector(2004)之實驗

- Grill-Spector(2004)之實驗結果
- fMRI資料顯示,FFA不只對是否看到臉有不同反應,也會因為受試者的反應正確與否而有不同的反應

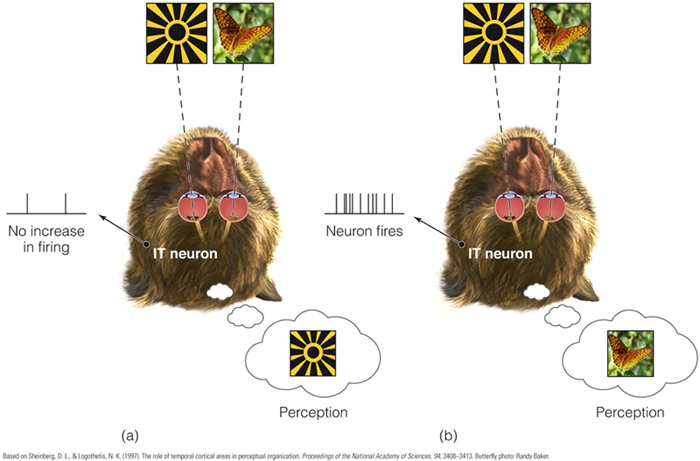
Sheinberg and Logothesis (1997)
- binocular rivalry
- IT上的細胞會根據猴子的主觀知覺是看到類似太陽的刺激還是蝴蝶而有不同的反應



Tong等人(1998)實驗
- 當觀看者,經驗到非臉,則:PPA>FFA,經驗到臉,則FFA>PPA

Voxels
- Voxels(volumetric pixel)
- fMRI Voxels2~3mm立方體
- Kamitani and Tong(2005) 可以由Voxels預測觀察者所見的傾斜方向

Kamitani and Tong(2005)
- 發現腦部反應可以預測觀察者的注意力是在哪個傾斜刺激上

Kay等人(2008)實驗
- 呈現1,750黑白照片
- 測量V1的500個voxels
- 整理voxels之活動之後
- 經過數學處理
- 由voxels的活動猜測觀察者所見
- 正確率72~92%
- Kay等人(2008)實驗結果
[[Image:05Kay.png】]
Structure encoding
- 觀看1750張圖
- 測量各voxel的活動
- 每一voxel對於不同圖的反應特性來計算該voxel 的特徵


Are faces special?

- face!!
- negative image

face in brain
- 可能有關的

- development


- development inf brain

- Think about


- 返回知覺心理學


